I love API’s! How do I know I really love an API? When I sit down on an evening and the next thing I know the birds start singing, thats how!
So when Salesforce first announced the Tooling API I’ve been following it closely and I am really pleased with the first version and what I’ve been able to achieve thus far with it. In the Spring’13 release it will be GA! Unsurprisingly like the Metadata API it provides CRUD (Create, Cread, Update and Delete) access to some of the key component types such as ApexClass, ApexTrigger and ApexPage. This list will grow in time. So whats the big deal you say? Well….
KEY FEATURES
The real magic is what this API brings in terms of the tasks and information around authoring and executing Apex and Visualforce. Such as Debug logs, Heap dumps and my personal favourite Symbol Tables!
A Symbol Table breaks down the code you write and gives you a kind of analytics over your code. Listing all the properties methods defined and also references elsewhere being made. This information is useful for all kinds of analysis, such as code refactoring and code complexity such as Cyclomatic complexity.
APEX CODE ANALYSIS TOOL
This blog presents the beginnings of a Apex Code Analysis Tool. While also showing via Force.com Canvas thats its now possible to add such a tool directly into your DE environment, no software download required!
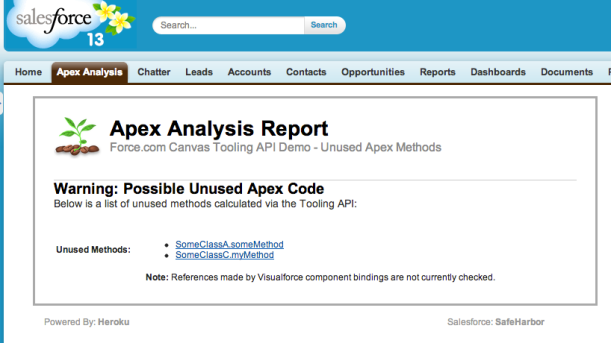
When refactoring code, its import to know what dependencies exist between your classes, methods and properties. So that you can decide on where to trim or consolidate code accordingly. I started with the requirement of wanting to know what methods are now no longer being referenced at all, and thus could be removed. This would also improve test code coverage as well. After achieving this analysis, the tool would have the data to be easily extended.
Installing
Before we get into the nitty gritty, I do want to say that I do plan once Spring’13 is out and the API is fully GA. To provide the usual Canvas app install link to make it a little easier for those of you that just want to try it out directly and not have to worry about compiling and deploying it, watch “this” space!
THE NUTS AND BOLTS
The code is written in Java and is essentially invoked via a JSP binding on the page shown above to list the methods. The tool itself uses the Force.com Canvas SDK running on Heroku to host the logic. The Canvas SDK provides access to the oAuth token to authenticate the Tooling API calls. The Canvas Developers Guide is an excellent place to learning more about this. The SDK itself is quite light and easy to use, only a few Java classes are needed, good job guys!
The next thing I needed, as Java is type safe language, was to download the Tooling API WSDL (there is also a REST interface for the Tooling API). This can be downloaded via [Your Name] > Setup > Develop > API. As this is Canvas app from the SDK, it uses Maven to build the code. I found WSDL2Java tool that would plugin into my pom.xml file in the form of JAX-WS xsimport. Armed with my client stubs I could access the Tooling API natively in Java. I’ve given more details on this on the github repo associated with this blog.
THE CODE
This first part of the code shows the Canvas SDK in action providing the oAuth token (line 6) from the information Canvas POST’s to the page. We need to create the usual SessionHeader (standard Salesforce API approach for authentication) and populate it with the token. We also create our client service (line 10) to call the Tooling API on. These classes have been created earlier by integrating the Tooling API WSDL via the WSDL2Java tool via the pom.xml file.
public class ToolingAPI {
public static String getUnusedApexMethods(String input, String secret)
{
// Get oAuth token
CanvasRequest request =
SignedRequest.verifyAndDecode(input, secret);
String oAuthToken = request.getClient().getOAuthToken();
// Connect to Tooling API
SforceServiceService service = new SforceServiceService();
SforceServicePortType port = service.getSforceService();
SessionHeader sessionHeader = new SessionHeader();
sessionHeader.setSessionId(oAuthToken);
Next we need to understand a little about the Tooling API and how to get things done with it. The Tooling API Developers Guide is a good read to get you started. Its is essentially a matter using CRUD operations on a set of new SObject’s it exposes. To setup whats described as a MetadataContainer, which I suspect relates to a Workspace if your used to using the Developer Console (which is now widely known to have been using the Tooling API for a while now).
- ApexClass, if your familiar with the Metadata API you will know about this object. Also if you have poked around with Schema tools will also know it as a means to query the Apex classes in an org.
- MetadataContainer. This is in a sense a parent object to the ApexClassMember object described below and is kind of your working environment in which you add other components to. It is pretty simple to create, it just needs a unique name.
- ApexClassMember. Not to be confused with a ‘member’ variable of an Apex class btw! This object is associated with the MetadataContainer via the MetadataContainerId field. It must also be associated with the related ApexClass, via its ContentEntityId field. After that you simply provide it a Body of the code you want the Tooling API to deal with. In this use case I’ve read that directly from the ApexClass object. This object also exposes an important child object, the SymbolTable. But only after we have asked the Tooling API to process it.
- ContainerAsyncRequest. So far the above objects have helped you set out your stall in respect to the code you want the Tooling API to deal with. Records inserted into this object will actually get it to do some processing. Again those familiar with the Metadata API will see some old favourites on here field wise. The key one for this use case, is the IsCheckOnly field. Setting this to True ensures we don’t actually update anything, all we need is the calculated SymbolTable!
The following code queries the ApexClass‘s we want to obtain the SymbolTable‘s for. Creates/recreates the MetadataContainer. Then creates and associates with it a number ApexClassMember’s for each of the ApexClass’s queried. After this stage we are ready for the magic!
// Query visible Apex classes (this query does not support querying in packaging orgs)
ApexClass[] apexClasses =
port.query("select Id, Name, Body from ApexClass where NamespacePrefix = null", sessionHeader)
.getRecords().toArray(new ApexClass[0]);
// Delete existing MetadataContainer?
MetadataContainer[] containers =
port.query("select Id, Name from MetadataContainer where Name = 'UnusedApexMethods'", sessionHeader)
.getRecords().toArray(new MetadataContainer[0]);
if(containers.length>0)
port.delete(Arrays.asList(containers[0].getId()), sessionHeader);
// Create new MetadataContainer
MetadataContainer container = new MetadataContainer();
container.setName("UnusedApexMethods");
List saveResults = port.create(new ArrayList(Arrays.asList(container)), sessionHeader);
String containerId = saveResults.get(0).getId();
// Create ApexClassMember's and associate them with the MetadataContainer
List apexClassMembers = new ArrayList();
for(ApexClass apexClass : apexClasses)
{
ApexClassMember apexClassMember = new ApexClassMember();
apexClassMember.setBody(apexClass.getBody());
apexClassMember.setContentEntityId(apexClass.getId());
apexClassMember.setMetadataContainerId(containerId);
apexClassMembers.add(apexClassMember);
}
saveResults = port.create(new ArrayList(apexClassMembers), sessionHeader);
List apexClassMemberIds = new ArrayList();
for(SaveResult saveResult : saveResults)
apexClassMemberIds.add(saveResult.getId());
The following code creates a ContainerAysncRequest record, which has the effect of kicking off a background process in the Salesforce servers to begin to process the members of the MetadataContainer provided to it. Note that we set the CheckOnly field to True here, as we don’t want to actual update anything. In this sample code we simply ask Java to wait for this operation to complete.
// Create ContainerAysncRequest to deploy the (check only) the Apex Classes and thus obtain the SymbolTable's
ContainerAsyncRequest ayncRequest = new ContainerAsyncRequest();
ayncRequest.setMetadataContainerId(containerId);
ayncRequest.setIsCheckOnly(true);
saveResults = port.create(new ArrayList(Arrays.asList(ayncRequest)), sessionHeader);
String containerAsyncRequestId = saveResults.get(0).getId();
ayncRequest = (ContainerAsyncRequest)
port.retrieve("State", "ContainerAsyncRequest", Arrays.asList(containerAsyncRequestId), sessionHeader).get(0);
while(ayncRequest.getState().equals("Queued"))
{
try {
Thread.sleep(1 * 1000); // Wait for a second
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
ayncRequest = (ContainerAsyncRequest)
port.retrieve("State", "ContainerAsyncRequest", Arrays.asList(containerAsyncRequestId), sessionHeader).get(0);
}
Next we requery the ApexClassMember‘s, requesting the SymbolTable information in the query. The code then scans through the SymbolTable information for each ApexClassMember looking for methods declared and methods referenced. Adding the resulting qualified method names in one of two Java Set’s accordingly for later processing.
// Query again the ApexClassMember's to retrieve the SymbolTable's
ApexClassMember[] apexClassMembersWithSymbols =
port.retrieve("Body, ContentEntityId, SymbolTable", "ApexClassMember", apexClassMemberIds, sessionHeader)
.toArray(new ApexClassMember[0]);
// Map declared methods and external method references from SymbolTable's
Set declaredMethods = new HashSet();
Set methodReferences = new HashSet();
for(ApexClassMember apexClassMember : apexClassMembersWithSymbols)
{
// List class methods defined and referenced
SymbolTable symbolTable = apexClassMember.getSymbolTable();
if(symbolTable==null) // No symbol table, then class likely is invalid
continue;
for(Method method : symbolTable.getMethods())
{
// Annotations are not exposed currently, following attempts to detect test methods to avoid giving false positives
if(method.getName().toLowerCase().contains("test") &&
method.getVisibility() == SymbolVisibility.PRIVATE &&
(method.getReferences()==null || method.getReferences().size()==0))
continue;
// Skip Global methods as implicitly these are referenced
if( method.getVisibility() == SymbolVisibility.GLOBAL)
continue;
// Bug? (public method from System.Test?)
if( method.getName().equals("aot"))
continue;
// Add the qualified method name to the list
declaredMethods.add(symbolTable.getName() + "." + method.getName());
// Any local references to this method?
if(method.getReferences()!=null && method.getReferences().size()>0)
methodReferences.add(symbolTable.getName() + "." + method.getName());
}
// Add any method references this class makes to other class methods
for(ExternalReference externalRef : symbolTable.getExternalReferences())
for(ExternalMethod externalMethodRef : externalRef.getMethods())
methodReferences.add(externalRef.getName() + "." + externalMethodRef.getName());
}
There is some filtering applied to the methods processed. To filter out test methods (sadly for now at least annotations are not visible, so some assumptions are made here). Also methods marked as Global will not likely be referenced but of course are logically referenced by code outside of the org, so these methods are also skipped. Finally on occasion in my Sandbox I did get my SymbolTable populated with methods from System.Test, I’ve raised this with Salesforce.
Finally its a matter of looping over the declared methods and checking if they are present in the referenced methods set. Then outputting our list of unreferenced methods back through the JSP page binding.
// List declaredMethods with no external references
TreeSet unusedMethods = new TreeSet();
for(String delcaredMethodName : declaredMethods)
if(!methodReferences.contains(delcaredMethodName))
unusedMethods.add(delcaredMethodName);
// Render HTML table to display results
StringBuilder sb = new StringBuilder();
sb.append("<table>");
for(String methodName : unusedMethods)
sb.append("<tr><td>" + methodName + "</td></tr>");
sb.append("</table>");
return sb.toString();
}
You can view the latest version of the code above in the Github repo here. In this screenshot I’ve enhanced the above a little to provide hyper links to the classes. You can view the Apex code used to test this here.

SUMMARY
It should be noted that the Tooling API does also appear to support Visualforce ‘components’ ( I am assuming this to mean in a general sense, so thus VF pages). The principles appear the same in terms of how you interact with it, see the ApexComponentMember object in the docs. As such currently the above code does not consider references to methods on VF pages, a topic for another blog and/or fellow contributor to the Github repo perhaps…
So there you have it! The possibilities are now finally open for the tools we’ve all been waiting for. As our Apex code bases grow along with the demands of our apps and our customers. I for one am looking forward to see what happens next from tools vendors with this API.
Links