In my new role, I am enjoying getting back into a favorite pastime of trawling through the release notes and Metadata API for the latest new features and changes. That’s right – I really do compare the Metadata API as it often uncovers smaller changes or draws attention to something I might have missed in clicking through the documentation. This blog is not exhaustive – it’s simply a quick list of things that caught my eye (thus far) from a more developer, architect, and general architecture perspective. Rest assured, a number of these have gone on the future blogs list for a deeper dive!

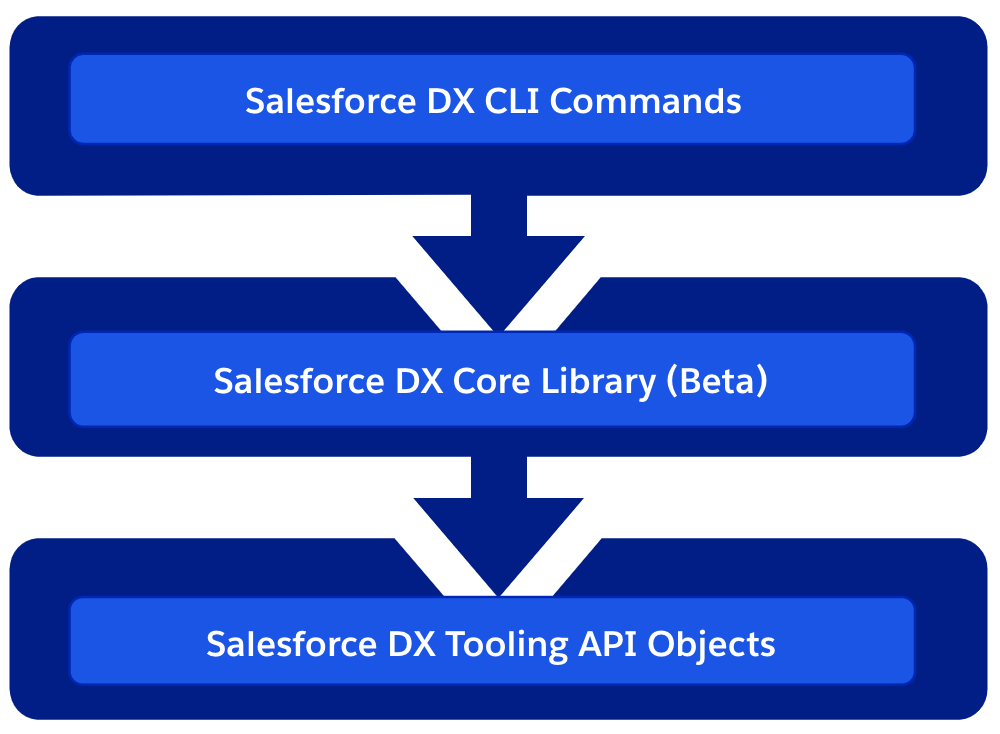
Integration Features and API Updates
- External Services continues to impress me with how easy it makes integrating well-documented (aka via OpenAPI schema) external APIs into Apex and Flow. It’s no longer just robotically generating stubs but adding actual platform integration value as well. With async APIs, it does a great job at integrating with platform callbacks. With Winter, it now sets its sights on binary information being passed around in APIs. Something that would easily blow heap limits today – per the documentation, it now appears that it will marshal binary content between ContentVersion records automatically. I literally had to write API code this week to manually write to this object myself to avoid a heap issue – now all I have to do is declare a binary type – nice!
- Make use of your Lightning Web Component investments outside of Salesforce with the return of a tech I explored a lot in the past, Lightning Out! Now we have Lightning Out v2.0 based on LWR (Lightning Web Runtime) which appears to have had a big refit and UX shake-up with a fancy new page under Setup that allows you to set up and list your external apps (websites) that want to access your LWC and provides a nice tool to provide the code needed to integrate.
- Make more use of industry web development innovation inside your Lightning Web Components with the ability to elevate third-party scripts to fully trusted mode. Having been around the block a number of times getting excited about a new widget or library to use in my Salesforce UIs only to find it’s blocked – this is a welcome option! It is behind, wisely a number of permissions to enable in the org – but at least we now have the option to make this decision ourselves – wonderful!
- Being more efficient with your LWC API requests is always a good thing! Sticking with LWC again, it’s great to see Salesforce investing in making native integrations with their APIs, such as the new GraphQL module
lightning/graphql– which replaces the now deprecatedlightning/uiGraphQLApi. This new version exposes access to optional fields and dynamic query construction. This is an area I have not really poked around in much – but I intend to now! - Now you can use Flow to more easily automate around changes in external systems – albeit if you have a Mulesoft license that is. Still this is a welcome addition showing that Salesforce is getting more serious about giving us a single pane of glass when it comes to their offerings and not forcing us to build glue integrations. This facility immediately, of course, leverages many existing Mulesoft connectors – allowing you, for example, to make a Flow that responds to Asana task completions or Calendly invites being accepted. Of course, we do have full Salesforce API support for invoking Flows as I have covered in the past – so you still have the DIY option to connect your Flows.
Developer Experience
- You can now access your Apex Controllers and Data from Local LWC (Beta). Local development still alas eludes Apex but less so LWC over the years. Salesforce is certainly ensuring web development on the platform is less jarring when coming from other platforms and frameworks here – with the ability to run your LWC locally and yet still have it access (deployed) Apex and data in the attached org. I do a reasonable amount of LWC development, and deploying (and refreshing) gets very tedious (even when AI-assisted) – so I think it’s about time with this new feature I took a deeper look at this.
- Logic is logic, no matter if it’s expressed as a Flow and/or Apex, and both need a good test solution. Thankfully, in later years, we have seen an uplift in recognizing this for Flow. And this release now brings together what I suspect has been scripted up until now – a more unified way of seeing Apex and Flow test results also see here.
- Standardizing documentation for Apex code has historically been a case of borrowing what largely JavaDocs has done – with the Winter release, Salesforce has now officially defined annotations for documenting Apex code – allowing tools to generate better docs and IDEs and AIs to better respond to the insights captured within them. I was not able to find more information other than release note topic at the time of writing – I am sure others will be eager to dive further into this for sure!
- A modern feature uplift for Salesforce packaging in the form of automatic dependency discovery. In the past, you had to list and manage the full dependency tree – now you can – much like other dependency managers elsewhere – define the immediate dependencies and have child dependencies automatically discovered. I suspect there will be a lot of attention to the details of how this one works once folks get their hands further on it – including myself.
Other Notables
This is already a long post – so my 10th area of interest is more of a catch all – so here are a few other things that also caught my attention:
- New Metadata Type – BatchProcessJobDefinition. This was observed only through comparing the Metadata APIs, I cannot find another reference to it other than here. Alas it appears to be less general purpose than its name implies – relating I believe to a feature in Loyalty cloud.
- Leverage Enhanced Field History Tracking
- Enable Field History Tracking for Users (Beta)
- Use Access Modifiers on Abstract and Override Methods (Apex)
- Enhanced Metadata Deployment Reliability with New Deployment States
- Easily Revert a Released First-Generation Managed Package Version to Beta
- Enhance Agent Action Input and Output UIs from the New Lightning Types Setup UI
- Enhance Invocable Apex Configuration Designs with New Action Extension Metadata | Type
- Build Agent-Driven Processes With Structured Outputs From Custom Agent Actions
p.s if you are interested in the output from my Metadata API compare – I uploaded it here. Maybe you can spot something cool or useful thats yet to be documented!


 I’m proud to announce the third edition of my book has now been released. Back in March this year I took the plunge start updates to many key areas and add two brand new chapters. Between the 2 years and 8 months since the last edition there has been several platform releases and an increasing number of new features and innovations that made this the biggest update ever! This edition also embraces the platforms rebranding to Lightning, hence the book is now entitled Salesforce Lightning Platform Enterprise Architecture.
I’m proud to announce the third edition of my book has now been released. Back in March this year I took the plunge start updates to many key areas and add two brand new chapters. Between the 2 years and 8 months since the last edition there has been several platform releases and an increasing number of new features and innovations that made this the biggest update ever! This edition also embraces the platforms rebranding to Lightning, hence the book is now entitled Salesforce Lightning Platform Enterprise Architecture.